The design and data exchange capabilities of Snowflake, on the other hand, set it apart. Customers can utilize and pay for storage and computation separately thanks to the Snowflake design, which allows storage and computing to scale independently. Organizations can also share controlled and protected data in real time thanks to the sharing capabilities.
Snowflake advantages for your company
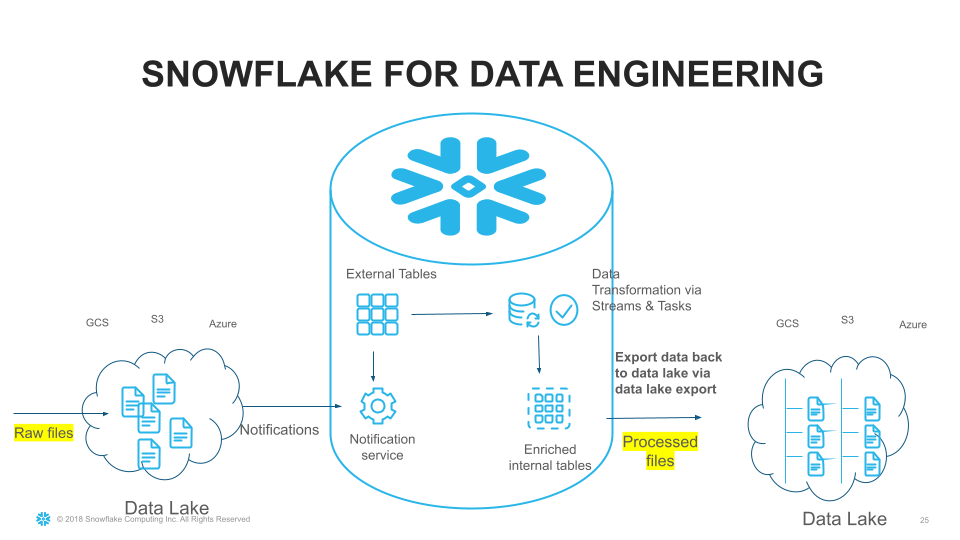
Snowflake is a cloud-native data warehouse that addresses many of the difficulties that plague previous hardware-based data warehouses, including restricted scalability, data transformation concerns, and delays or failures caused by heavy query volumes. Here are five ways that Snowflake can help your company.
Performance and quickness
Snowflake is used to manage around 500TB of data sets. If you need to load data quicker or run a high number of queries, you may scale up your virtual warehouse to make use of more compute resources thanks to the cloud’s elasticity. The virtual warehouse can then be shrunk, and you will only be charged for the time you used it.
Structured and semi-structured data storage and support
For analysis, you can aggregate structured and semi-structured data and load it into a cloud database without first converting or transforming it into a set relational schema. Snowflake improves the way data is automatically saved and queried.
Data exchange that is seamless
The architecture of Snowflake allows users to share data with one another. It also enables enterprises to share data with anyone, whether or not they are a Snowflake customer, via reader accounts generated straight from the user interface. This functionality allows the provider to create and manage a Snowflake account for a customer.
Accessibility and concurrency
Concurrency issues might arise when too many queries compete for resources in a typical data warehouse with a large number of users or use cases.
Snowflake’s multi-cluster architecture solves concurrency problems by ensuring that queries from one virtual warehouse never affect queries from another. Each virtual warehouse has the ability to scale up or down as needed. Data analysts and data scientists may get what they need right away without having to wait for other loading and processing operations to finish.
Security and availability
Snowflake is distributed throughout the platform’s availability zones, which are either AWS or Azure, and is designed to operate constantly while tolerating component and network failures with minimal user impact.